
記事の概要
MarpはMarkDownからpptx/pdfを生成でき、素敵なのですがMS365等でチーム作業する時に困ります。
それに生成される内容がテキストではなく、画像のような形式でスライドが張り付くので元のmarkdonも共有しないといけないので二度手間感があり苦慮してました。
GenSparkに聞いたら、Marpを利用するのではなく、PythonでMarkDownからpptxを生成することができるライブラリがあるそうなのでスクリプトを作成しました。
Pythonスクリプトの利用: 編集可能なPPTXファイルを作成するためには、Pythonスクリプトを使用する方法もあります。このスクリプトはMarkdownファイルから直接編集可能なPPTXファイルを生成します。具体的には、特定のMarkdown記法に従った内容を持つファイルを用意し、そのファイルをスクリプトに渡すことで変換が行われます
できること
Marp用に書いたMarkDownをPythonで変換する
想定環境等
- Google Colaboratory
利用するライブラリ
- python-pptx
- markdown
インストールコマンド
pip install python-pptx markdown
- inputファイル名
presen.md
- outputファイル名
presen.pptx
利用するスクリプト
from pptx import Presentation
from pptx.util import Inches, Pt
from pptx.enum.text import PP_ALIGN
from pptx.dml.color import RGBColor
import markdown
import re
class MarkdownToPPTX:
def __init__(self):
self.prs = Presentation()
self.code_font_size = Pt(14)
self.normal_font_size = Pt(18)
def process_code_block(self, text_frame, code):
paragraph = text_frame.add_paragraph()
paragraph.font.size = self.code_font_size
paragraph.font.name = 'Courier New'
paragraph.text = code.strip()
def process_bullet_points(self, text_frame, lines):
for line in lines:
if line.startswith('- '):
p = text_frame.add_paragraph()
p.text = line[2:].strip()
p.level = 0
p.font.size = self.normal_font_size
def clean_content(self, content):
# Marpのメタデータと空行を削除
content = re.sub(r'^---\s*\nmarp:.*?---\s*\n', '', content, flags=re.DOTALL)
content = re.sub(r'^style:.*?---\s*\n', '', content, flags=re.DOTALL)
return content.strip()
def split_slides(self, content):
# スライドを分割し、空のスライドを除外
slides = [slide.strip() for slide in content.split('---') if slide.strip()]
return slides
def get_slide_title(self, content):
# # または ## で始まる最初の行をタイトルとして抽出
title_match = re.search(r'^(#{1,2})\s+(.+)$', content, re.MULTILINE)
if title_match:
return title_match.group(2).strip()
return None
def get_slide_content(self, content):
# タイトル行を除いたコンテンツを取得
lines = content.split('\n')
content_lines = []
skip_next = False
for i, line in enumerate(lines):
if skip_next:
skip_next = False
continue
if re.match(r'^(#{1,2})\s+.+$', line):
continue
# h3見出し(###)の処理
if line.startswith('### '):
content_lines.append(line[4:]) # ### を除去
skip_next = False
else:
content_lines.append(line)
return '\n'.join(content_lines).strip()
def create_slide(self, content):
slide = self.prs.slides.add_slide(self.prs.slide_layouts[1])
# タイトルの処理
title = self.get_slide_title(content)
if title and slide.shapes.title:
slide.shapes.title.text = title
# コンテンツの処理
if slide.placeholders[1]:
tf = slide.placeholders[1].text_frame
# コンテンツの取得
slide_content = self.get_slide_content(content)
# コードブロックの処理
code_blocks = re.finditer(r'```(.*?)```', slide_content, re.DOTALL)
last_pos = 0
for match in code_blocks:
# コードブロック前のテキストを処理
pre_text = slide_content[last_pos:match.start()].strip()
if pre_text:
p = tf.add_paragraph()
p.text = pre_text
# コードブロックを処理
self.process_code_block(tf, match.group(1))
last_pos = match.end()
# 残りのテキストを処理
remaining_text = slide_content[last_pos:].strip()
if remaining_text:
# 箇条書きの処理
bullet_points = re.findall(r'^-\s+.+$', remaining_text, re.MULTILINE)
if bullet_points:
self.process_bullet_points(tf, bullet_points)
else:
p = tf.add_paragraph()
p.text = remaining_text
def convert(self, md_file, output_pptx):
with open(md_file, 'r', encoding='utf-8') as f:
content = f.read()
# コンテンツのクリーニング
content = self.clean_content(content)
# スライドの分割
slides = self.split_slides(content)
# 各スライドの処理
for slide_content in slides:
self.create_slide(slide_content)
# 保存
self.prs.save(output_pptx)
converter = MarkdownToPPTX()
converter.convert('presen.md', 'presen.pptx')
動作イメージ
- markdown
---
marp: true
theme: default
style: |
section {
background-color: #ffffff;
padding: 20px;
}
h1 {
color: #2c3e50;
border-bottom: 2px solid #3498db;
padding-bottom: 10px;
}
h2 {
color: #2980b9;
}
h3 {
color: #34495e;
}
code {
background-color: #f8f9fa;
border-radius: 4px;
padding: 2px 4px;
}
---
# MarkDown製のスライドを編集したい!
This Slide from markdown
## 編集できるの?
### できます!
全てはPythonの力...
### どうして?
ライブラリの力を借りて、テキストとして出力しているから
---- 生成するPPTXのスクショ
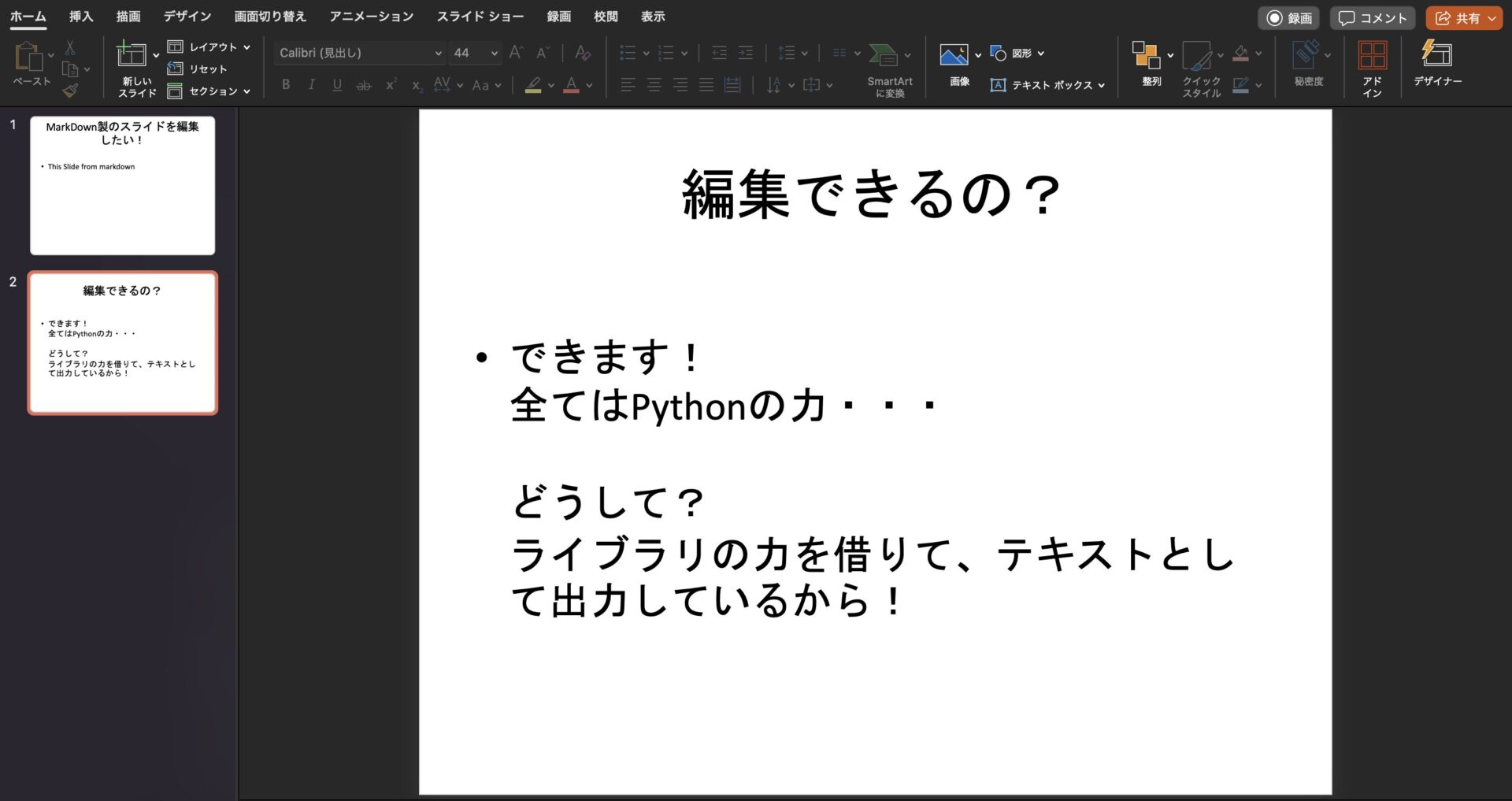
編集について
テキストが配置されているだけなので、PowerPoint自体のテーマやデザイナー機能で整えたりできる。
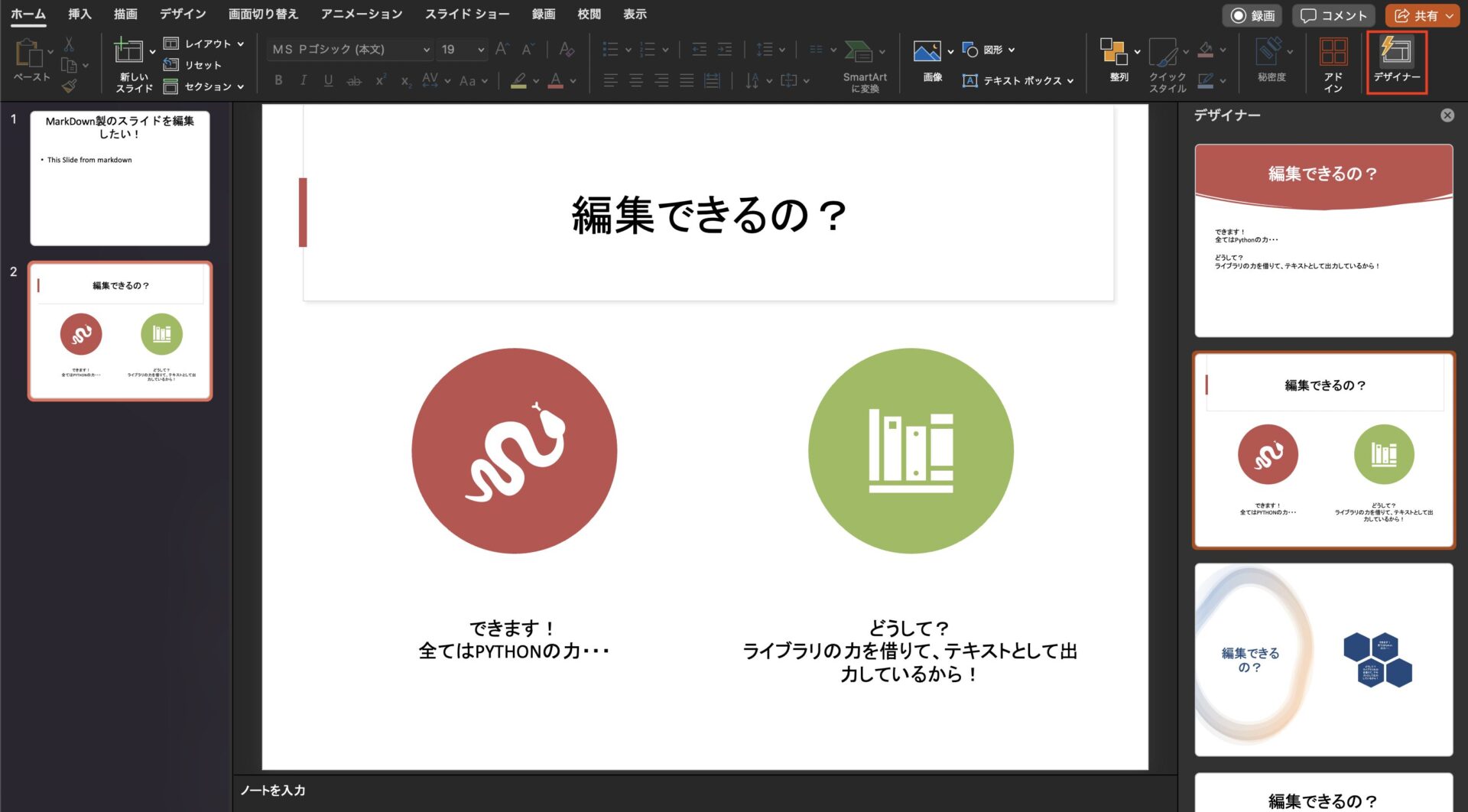
ある程度できたら、共有領域にアップロードして、みんなで作業してHappyHappy
最後に
似た(?)ような事項をnoteの有料記事で販売している方もいますが、それには及ばないと思います。
ですが、十分使用できるレベルにはなっていると思うので、活用してくださいませ。
以上、どなたかのお役に立てば幸いです